Our CI/CD in Istio is fairly slow, despite many hours of optimizations.
In this post, I will explore what a hypothetically ideal CI system might be, to optimize test execution time while keeping costs reasonable.
This isn't meant to be a good idea - the proposed system has a lot of issues. The intent here is just to explore how we can maximize test speed, at expense of anything else.
Current state
We run about 15-20 integration tests, that consist of:
- Create a Kubernetes cluster
- Build Istio images
- Install Istio
- Run a variety of tests
- Repeat 3-4 with different setups.
We have about 45 actual tests, but we somewhat arbitrarily divide them into different jobs to keep things running quickly. We also repeat some of the same tests with different configurations (such as different Kubernetes versions or settings).
These take 5-45mins, depending on luck, cache state, and the job size (multi-cluster ones are slowest).
A trace of one of our faster jobs:
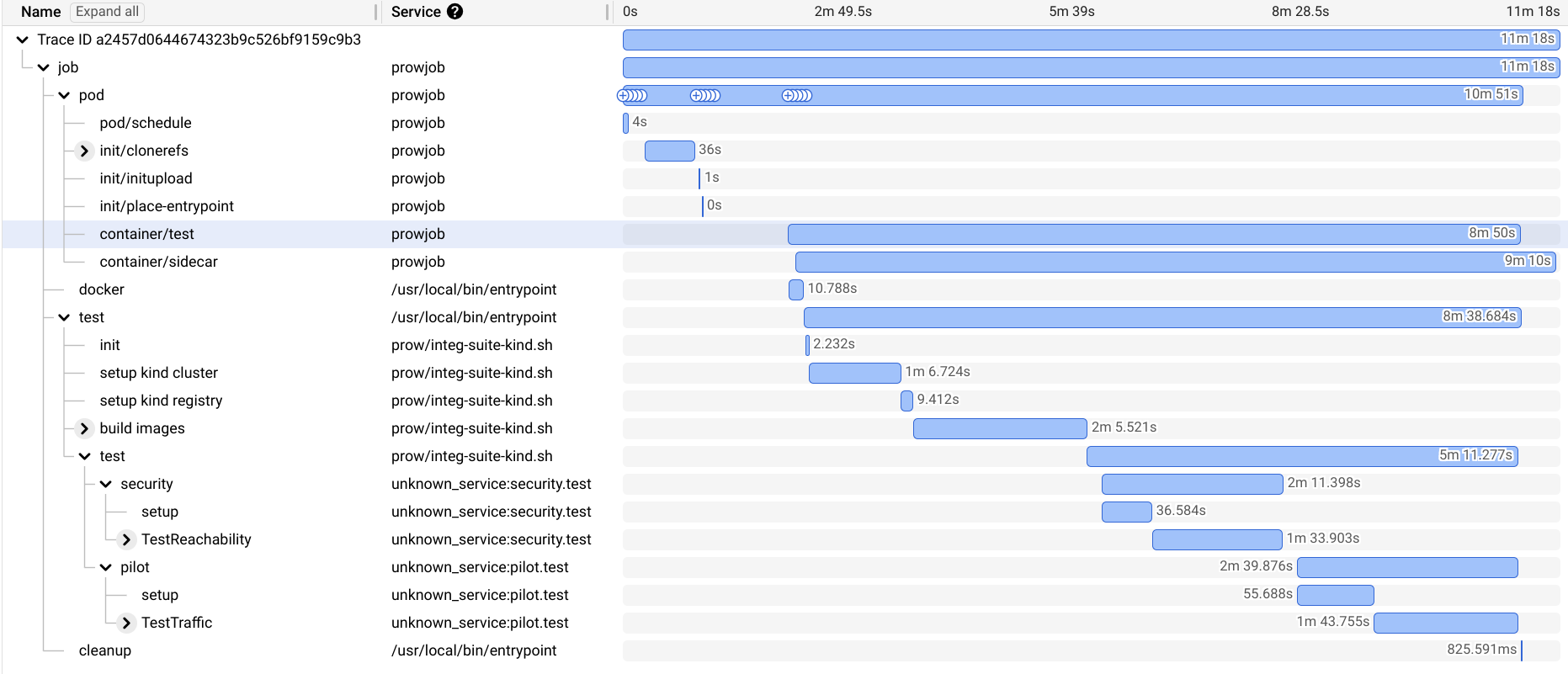
With the time spent broken down:
| Step | Time | Overall |
|---|---|---|
| Total | 678s | 100.00% |
| Git clone | 36s | 5.31% |
| Image pull | 75s | 11.06% |
| Cluster setup | 75s | 11.06% |
| Image Build | 125s | 18.44% |
| Test Compile | 20s | 2.95% |
| Test Setup | 92s | 13.57% |
| Test Execution | 196s | 28.91% |
| Post Test | 30s | 4.42% |
We can see while our total time here is 11min, only 3min (~25%) is actually spent running tests.
Our hypothetical optimal is not really 3 minutes, though. This is executing 2 packages (about 90s each), each with many subtests. So we could go smaller.
Current Architecture
Currently, our CI/CD platform is prow. This isn't too important, it mostly just schedules a Kubernetes Pod for each job we run, and we have ~full control over the Pod.
Our test pods use a (large) image with everything we need in it, rather than installing dependencies on-demand. This is usually cached on the node.
The main optimizations we apply, aside from roughly partitioning the tests and making each step as fast as possible, is mounting a node-local cache for go builds and modules.
In the above trace, I must have gotten a new node, so there was no cached image or build cache to rely on.
One thing that is terrible about this approach is that each test job is completely independent. This means each job is building the same images, etc. Our platform has no DAG, only a list of jobs to run.
Ideal state
Right off the bat, some obvious things we will want.
Shared builds
Caching builds is table stakes. Building only once instead of N times is the next step, so we will need to get a CI/CD platform with a DAG execution:
A initial task can do all the image building. However, it will need to store the state somewhere for the jobs to read. A docker image registry should work here.
However, this is probably worse than the current state if the jobs just do go test ./... after.
Compiling the tests has a ton of overlap with compiling the images. So while this will shave off the "build images" time, it will almost certainly increase the later step time.
Instead, the builder can also build the tests (go test -c can compile tests without executing them).
This can then be passed to the tests, which simply run them as a binary. The test environment wouldn't even need go in most cases.
Sharing state
This common builder task doesn't really speed things up. It de-duplicates work, but that work was done in parallel.
It does have a decent cost saving potential, though, as we can make the build task run on large machines and the test executors smaller machines (which, in turn, may be a bit faster).
Using a stateful builder may help resolve these problems though. Using a single (very very large) builder between runs can allow us to share a ton of state to speed things up.
- Git clones (5% of execution) can be near instant, as they just need to pull the incremental change. This can be cheap using
git worktreeas well. - Go modules and build cache can be re-used.
With this new approach, we can also parallelize some of the test setup. When a new pipeline is kicked off, in parallel:
- We tell the builder to start building the images and test binaries
- We spin up a few workers. They can setup immediately (spin up a cluster, etc), then wait for the builder to be complete enough for them to actually start testing.
No setup
While we are pretty parallelized now -- our cluster setup happens concurrently with building -- having a slow setup phase limits us. If tests take 10s each but setup is a minute, we probably want to have fewer test runners. If setup is fast, though, its more efficient to scale out and have more concurrency.
On most platforms, running N tasks in sequence on a single machine and running 1 task on N machines will cost the same, as long as the time is the same for each task. If setup is trivial, then we meet this property and can more aggressively parallelize our jobs.
Instead of running an image with our dependencies and then starting long-running processes, we can instead start the long processes and snapshot the state once they are ready. This can be done in docker, firecracker, and others. This makes our startup phase nearly instant.
New architecture
With this pieces in place we end up with something like this:

When a change needs testing:
- The large builder instance picks it up
- It clones the changes (fast, due to our changes above)
- Builds images and test binaries
- As each test binary is ready, we trigger a new test runner to execute it
Our (completely made up) test timing now looks like:
| Step | Time | Overall |
|---|---|---|
| Total | 171.0s | 100.00% |
| Git clone | 1.0s | 0.58% |
| Image pull | 0.0s | 0.00% |
| Cluster setup | 0.0s | 0.00% |
| Image Build | 5.0s | 2.92% |
| Test Compile | 5.0s | 2.92% |
| Test Setup | 45.0s | 26.32% |
| Test Execution | 100.0s | 58.48% |
| Post Test | 15.0s | 8.77% |
58% of time is spent running our tests now (and 85%, if we include our application-specific test setup, which is kind of part of the test). This is up from 28%/42%.
Our total runtime is also 4x faster than before.
Going further
One thing that still bugs me about this approach is that the builders may be processing multiple changes at once.
Go is not good at compiling multiple things in separate go invocations.
What we really want is a long running go build daemon, that can add actions to run to efficiently deduplicate these across calls.
At a very high level this seems plausible.
The go compiler works by building a DAG of steps to process, so we "just" need to merge two DAGs together.