I've spent the majority of my career building Istio's control plane, Istiod, with an emphasis on making it highly performant and scalable. And while it has come a very (very) long way, it's still a long way off from what a control plane could be.
It's not alone. When I worked on building an open benchmark of Kubernetes Gateway control planes, I was surprised to find that no implementation met what I felt was a reasonable bar for a "highly scalable and performant control plane".
This isn't for lack of trying. On the Istio side, we've tried countless tricks to optimize things. Many caching layers, micro-optimizations, and other tricks each brought incremental improvements -- 5% faster here, 25% there. But these were just band-aids, not solutions to the fundamental architectural issues.
Over the past few years, I've had the opportunity to build two new proxies from the ground up, and with them, their control planes:
- Ztunnel, the network transport layer for Istio ambient mode
- Agentgateway, a next-generation AI-native proxy
Both of these were built on the same underlying principle that led to an order of magnitude improvement over comparable solutions.
The root of all problems
In software optimization, doing less work is always a better strategy than doing the same amount of work faster. A fancy SIMD algorithm is fun, but doing nothing is even faster (and easier).
If we look at the expensive work a control plane does, it almost invariably comes down to a fan-out of data. The user performs a small input action (like modifying one configuration knob), and the control plane needs to do a disproportionate amount of work to actuate that change.
Let me give a simple example. Istio offers a global configuration setting to control the minimum TLS version. A user can change this in seconds, and from their perspective, they are simply setting one integer field. To actuate this change, Istio's control plane needs to push down new information about every service to every workload instance. This is an O(N^2) operation and can result in hundreds of gigabytes of data transferred at large scales—all from changing a single integer.
This mismatch isn't due to a suboptimal control plane implementation, but a fundamental disconnect between the APIs.
The Three Surfaces of Configuration
In any control plane architecture, there are three different configuration surfaces that must be considered:
- User Intent: What the user wants to achieve. This is often overlooked but is the most important aspect (for example, "I want to enforce TLS 1.3 globally").
- User-Facing API: The API that users interact with. In a Kubernetes project, this would typically be a Custom Resource (for example, a global
MeshConfigsetting). - Data Plane API: The internal API the control plane uses to configure the proxy (for example, Envoy's XDS API).
A scalable control plane is born when these three surfaces are in harmony. When they are disjoint, we run into the expensive fan-out scenarios described above, and performance suffers.
Most projects build out the APIs, and then later try to scale the control plane, and run into endless walls because you cannot out-optimize a bad design.
If we look back at the above example, the user facing and data plane API are disjoint. Because of this, the control plane is forced to perform a massive fan-out to implement the user's intent.
What if we "fixed" this by removing the global setting from the user-facing API and only offered a per-service value? The user-facing API and data plane API would now be in harmony... but we've just pushed the problem to the user! Now, to achieve their goal, the user themselves has to configure every single service. This is even worse for everyone: the user needs to do more work, and the control plane does as well!
In the real world
When applied, these principles seem to invariably cause massive performance wins.
Kubernetes itself applied this approach when building EndpointSlice, a replacement for Endpoints.
While Endpoints aggregated all pods (sometimes thousands) into a single object (fan out!), EndpointSlice chunks them up into sections of 100 pods each (100 was chosen rather than 1-to-1 due to the per-object overhead of Kubernetes), leading to >10x performance improvements.
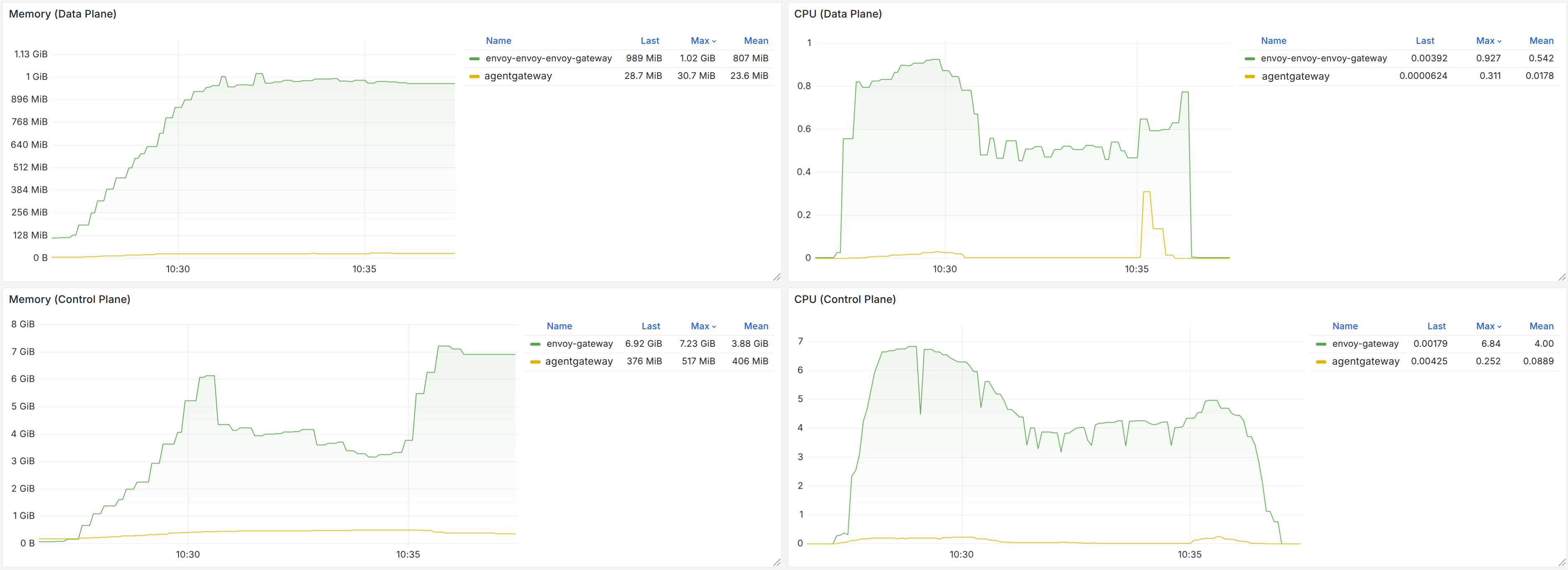
In Istio ztunnel, the results were even more pronounced, in some cases offering 100x or greater improvements:
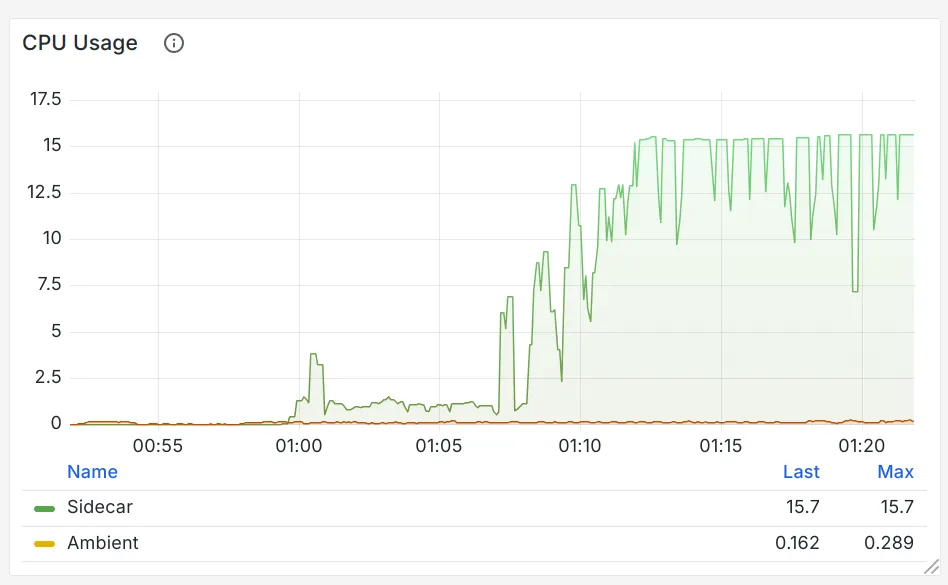
In agentgateway, similar numbers were attained. While offering the exact same user facing API, by aligning the data plane API with the user facing API, utilization dropped by 25x!